GCPのログ監視の概要とログベースのアラートをTerraformの実装例を交えて説明します。題材としてCloud Schedulerの失敗の監視を取り扱います。
前提
- Terraform、GCPの基礎知識を持っている読者を想定しています。
ログ監視
ログ監視による異常検知
問題があったらまずログを見るというのはエンジニアの鉄則ですね。つまり、ログには問題を検知するために有用な情報が含まれているのです。ログ監視ではログを異常検知などに活用します。「ログ監視」で調べると不正侵入などに焦点を当てたセキュリティに関わる記事が多く見つかる気がします。クラウドを活用する場合は、メトリクスなどが用意されていない場合の異常検知などにもとても有効です。その一例が今回紹介するCloud Schedulerの失敗検知です。Cloud Schedulerは失敗したかどうかのメトリクスなどを提供していないため、失敗検知に一工夫必要になります。
GCPのログ監視
GCPではログ監視によるアラート発報方法が大きく2つあります。以下表に特徴をまとめました。*1
| 項目 | ログベースのアラート | ログベースの指標のアラート |
|---|---|---|
| 用途 | 特定ログの発生を検知する。イベントログなどで特定イベントが発生した場合の検知などに適している。 | ログの発生数に応じて検知する。特定のログ数が一定の閾値を超えた場合の検知などに適している。 |
| 具体例 | Cloud Schedulerの失敗ログを検知する。 | アプリケーションのログで「login failed」が15分以内に100個以上発生した場合を攻撃として検知する。 |
ログ数を用いた検知ロジックを使いたければ「ログベースの指標のアラート」を利用すると考えておけば良いと思います。当記事では「ログベースのアラート」について説明をします。
Terraformのサンプル実装と解説
それではサンプルコードとポイントとなる部分を解説します。
リポジトリ:paper2/log-based-alerts-terraform-sample
# 失敗するCloud Scheduler Job resource "google_cloud_scheduler_job" "sample_fail_job" { name = "sample-fail-job-${local.name_suffix}" description = "Sample http job. This job always fails." schedule = "*/15 * * * *" attempt_deadline = "300s" retry_config { retry_count = 3 min_backoff_duration = "80s" } http_target { http_method = "GET" # This URL is not existed. uri = "https://goog1e" } } # 通知先 resource "google_monitoring_notification_channel" "test_notification_channel" { display_name = "Test Notification Channel" type = "email" labels = { email_address = local.notification_channel_email } } # ログベースのアラート resource "google_monitoring_alert_policy" "sampole_log_based_alert" { display_name = "Cloud Scheduler Faild Alert" combiner = "OR" conditions { display_name = "Log match condition" condition_matched_log { filter = <<-EOF resource.type="cloud_scheduler_job" resource.labels.job_id="${google_cloud_scheduler_job.sample_fail_job.name}" severity=ERROR jsonPayload.@type="type.googleapis.com/google.cloud.scheduler.logging.AttemptFinished" EOF } } notification_channels = [google_monitoring_notification_channel.test_notification_channel.id] alert_strategy { notification_rate_limit { period = "300s" } auto_close = "604800s" } documentation { content = "Cloud Scheduler(job_id:${google_cloud_scheduler_job.sample_fail_job.name}) faild." } }
google_cloud_scheduler_job
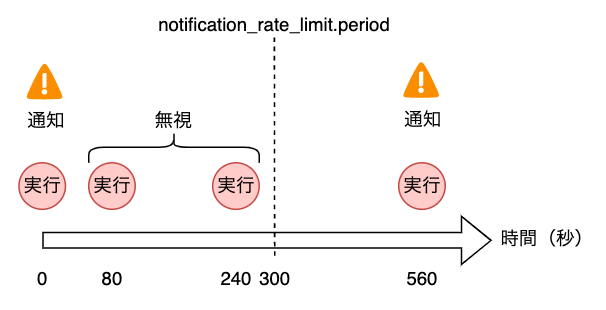
Cloud Schedulerです。HTTPでリクエストを投げますがURIにタイポがあるので、このジョブはすぐに失敗します。そのため、下図のようにリトライを含めて4回ジョブが実行され、全て失敗します。

google_monitoring_notification_channel
通知先をEmailで設定しています。
google_monitoring_alert_policy
ログベースのアラートの定義です。メトリクスのアラートポリシーとリソースは同じです。大きな違いは conditions内でメトリクスではcondition_thresholdで条件を書きますが、ログベースのアラートではcondition_matched_logを利用します。
conditions.condition_matched_logにはLog Explorerと同様のクエリを記載します。このクエリの結果、ログが存在するとアラートが発報されます。クエリの実行周期などを指定するオプションはないですが、Slack通知で設定していた場合は大体30秒しないくらいで通知がくるのでまあまあ早いのかなという気がします。
alert_strategy.notification_rate_limit.periodもログベースのアラート特有の設定です。アラート発報後、指定した時間内はクエリに該当する新しいログがあっても無視する機能です。今回の例では300sで設定しているので、3回の実行は1つの通知でまとめられます。4回目の再実行は再度通知が来ます。本来であれば4回目の通知は受け取りたくないので、periodを長くすることが必要です。メトリクスのアラートではインシデントがオープン中はconditionを満たしていても再通知されませんが、ログベースのアラートではインシデントがオープン時でも再通知がくるのが特徴です。
なお、お気づきの方もいらっしゃると思いますが上記の例ではリトライで成功した場合も失敗通知が来てしまいます。なのでリトライの成功も考慮して失敗通知をする場合は実はログベースの指標のアラートが適しています。今回は仕様の説明のためにこのような構成にしています。
まとめ
GCPのログ監視の概要とログベースのアラートをTerraformの実装例を交えて説明しました。
*1:公式ドキュメントでは「ログベースのアラート」と「ログベースの指標」という言葉で比較しています。比較するものがあっていない気がしたので、「ログベースのアラート」と「ログベースの指標のアラート」という表現にしています。